First published 13/06/2012 at http://grahamdavey.blogspot.co.uk

Why doesn’t every student in Higher Education get awarded a first class degree? Is it because they’re not intelligent enough? Is it because they’re not taught effectively? Is it because a majority of students are plain lazy? Is it because they are too spoon-fed? Well no, it’s none of those. It’s because most Universities haven’t yet fine-tuned their assessment and classification systems in a way that will allow all students – regardless of ability and potential – to get a first class degree. A majority of Universities have adjusted their assessment and classification schemes to a point where only the most delinquent of students will attain anything less than an upper-second class degree, but there is still some fine-tuning required to turn out close to 100% first class students.
Here are some tips for those Universities and institutions still striving for this level of perfection. Individually none of these factors is necessarily bad practice or illegal, and indeed many institutions strive to introduce many of these factors as examples of innovative good practice. However, if you put them all together in one scheme, you create an assessment and classification system that can turn the most delinquent and uninspiring student into a first class success. Here are the basic elements of that system:
1. Always adopt a categorical marking scheme. Make sure that the first class band of marks covers 30% of awardable marks (e.g. 70-100%) whereas other classification bands cover only 10% (e.g. upper second class from 60-69%). Within the first class band of marks, make sure there are as few categorical marks available to be awarded as possible and that there is a giant leap in awardable marks between a low first and a good first. For example, make the following marks the only ones awardable in the first class band, 75%, 90% and 100%. Then make sure that the assessment guidelines for 90% are as similar as possible to 75%, but with an added factor that all first class scripts would normally possess (e.g. to be awarded 90% a piece of work must have all the characteristics of a piece of work worthy of 75%, but will show “evidence of breadth of reading”).
2. Always make sure that each piece of work is double marked, and that any discrepancies between markers are rounded up (e.g. if one marker awards 75% and the second awards 95%, then award 95%).
3. Allow all final year students a resit option on failed papers that is not capped at the basic pass mark. Indeed, also consider allowing final year students the opportunity to resubmit any piece of work where they are not satisfied with the original mark.
4. Include MCQs as a highly weighted component of every course/module – at both second and final year. Ensure that these MCQs are taken from a limited bank of questions that is recycled every year. Conveniently forget to adjust the marks on these MCQs for the possibility of chance correct answers.
5. Include as many assessments as possible where the student has the opportunity to score 100% (e.g. MCQs, assessments where there is an indisputable correct answer or answers, etc.)
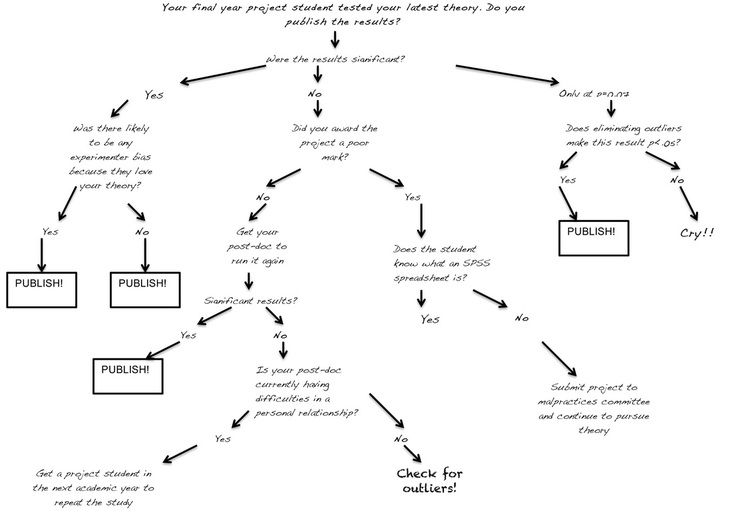
6. Have at least one course/module in the final year that is weighted to make up most of the marks for that year (e.g. a final year project/dissertation). Ensure that the credit weighting of this course is excessive (e.g. the equivalent to 4 other courses), but that the work required by the student is nowhere near equivalent to the work required of four courses. Make sure the students are aware that this is a course/module on which they should concentrate their efforts.
7. Adopt a very liberal classification borderline “bumping up” scheme that will ensure that as many students below a borderline will meet the criteria for being “bumped up” into the higher classification bracket even if they haven’t achieved the required aggregate mark for that higher classification bracket. Make sure that this is a mechanistic “bumping up” process determined by an algorithm (don’t involve the external examiners in this process – they may question it!)
8. Introduce changes to the assessment and classification processes every year. This will mean that students will usually be simultaneously graded by two schemes – the “old scheme” and the “new scheme”, and all candidates will be classified according to their ‘best’ outcome from either of the schemes.
9. Encourage students to apply for concessions and submit mitigating evidence. Make this process as simple as possible and do not set deadlines for evidence to be submitted. In particular, allow mitigation to be submitted after the student has knowledge of their degree classification.
10. Allow external examiners to adjust agreed marks. But only upwards, so as not to unnecessarily disadvantage any student.
11. No need to make candidates' identities anonymous. Some good students may have an off day in the exams and names on scripts will allow the internal examiner to mark the candidate according to their ability rather than on an exam "off day". Poor students who perform above their expected ability in an exam can be identified and rewarded accordingly.
12. External examiners need pacifying and domesticating. Make sure that they have comfortable hotels and are given expensive dinners. Always tell them that there have been IT problems in the Registry and a full summary of marks and assessment statistics is unavailable this year. Fabricate at least two admin staff illnesses which have meant that scripts and coursework could not be sent to the external for moderation. Compliant externals should also be appointed for additional years after the end of their term of office. Make sure it is clear to externals that assessment guidelines (and anything else they may query) have been imposed by the University central administration and are out of the control of the Department. Regularly change Departmental Exam Officers so that no one individual can acquire enough knowledge to ensure the assessment period is conducted according to the full set of regulations.
13. If an external examiner attempts to question the objectivity and validity of an examination and assessment process, the Registry should reply by stating that there was not a critical mass of external examiners across disciplines raising this particular issue to require a change in University policy. University Registries should ensure that the full range of external examiners' reports are not compiled in any single place where they are freely available for general scrutiny.
14. Finally, make sure that a directive comes down from the University Registry to all examiners to “mark generously and use the full extremes of the marking scales – especially the first class band of marks”. This, of course, is imperative if the institution is to achieve a good grading in forthcoming National Student Surveys!
Please feel free to suggest more practical ideas by which Universities can adjust their assessment and classification processes to generate increasing percentages of first class students. Don't forget, well qualified graduates are our future - we need more of them!
Here are some tips for those Universities and institutions still striving for this level of perfection. Individually none of these factors is necessarily bad practice or illegal, and indeed many institutions strive to introduce many of these factors as examples of innovative good practice. However, if you put them all together in one scheme, you create an assessment and classification system that can turn the most delinquent and uninspiring student into a first class success. Here are the basic elements of that system:
1. Always adopt a categorical marking scheme. Make sure that the first class band of marks covers 30% of awardable marks (e.g. 70-100%) whereas other classification bands cover only 10% (e.g. upper second class from 60-69%). Within the first class band of marks, make sure there are as few categorical marks available to be awarded as possible and that there is a giant leap in awardable marks between a low first and a good first. For example, make the following marks the only ones awardable in the first class band, 75%, 90% and 100%. Then make sure that the assessment guidelines for 90% are as similar as possible to 75%, but with an added factor that all first class scripts would normally possess (e.g. to be awarded 90% a piece of work must have all the characteristics of a piece of work worthy of 75%, but will show “evidence of breadth of reading”).
2. Always make sure that each piece of work is double marked, and that any discrepancies between markers are rounded up (e.g. if one marker awards 75% and the second awards 95%, then award 95%).
3. Allow all final year students a resit option on failed papers that is not capped at the basic pass mark. Indeed, also consider allowing final year students the opportunity to resubmit any piece of work where they are not satisfied with the original mark.
4. Include MCQs as a highly weighted component of every course/module – at both second and final year. Ensure that these MCQs are taken from a limited bank of questions that is recycled every year. Conveniently forget to adjust the marks on these MCQs for the possibility of chance correct answers.
5. Include as many assessments as possible where the student has the opportunity to score 100% (e.g. MCQs, assessments where there is an indisputable correct answer or answers, etc.)
6. Have at least one course/module in the final year that is weighted to make up most of the marks for that year (e.g. a final year project/dissertation). Ensure that the credit weighting of this course is excessive (e.g. the equivalent to 4 other courses), but that the work required by the student is nowhere near equivalent to the work required of four courses. Make sure the students are aware that this is a course/module on which they should concentrate their efforts.
7. Adopt a very liberal classification borderline “bumping up” scheme that will ensure that as many students below a borderline will meet the criteria for being “bumped up” into the higher classification bracket even if they haven’t achieved the required aggregate mark for that higher classification bracket. Make sure that this is a mechanistic “bumping up” process determined by an algorithm (don’t involve the external examiners in this process – they may question it!)
8. Introduce changes to the assessment and classification processes every year. This will mean that students will usually be simultaneously graded by two schemes – the “old scheme” and the “new scheme”, and all candidates will be classified according to their ‘best’ outcome from either of the schemes.
9. Encourage students to apply for concessions and submit mitigating evidence. Make this process as simple as possible and do not set deadlines for evidence to be submitted. In particular, allow mitigation to be submitted after the student has knowledge of their degree classification.
10. Allow external examiners to adjust agreed marks. But only upwards, so as not to unnecessarily disadvantage any student.
11. No need to make candidates' identities anonymous. Some good students may have an off day in the exams and names on scripts will allow the internal examiner to mark the candidate according to their ability rather than on an exam "off day". Poor students who perform above their expected ability in an exam can be identified and rewarded accordingly.
12. External examiners need pacifying and domesticating. Make sure that they have comfortable hotels and are given expensive dinners. Always tell them that there have been IT problems in the Registry and a full summary of marks and assessment statistics is unavailable this year. Fabricate at least two admin staff illnesses which have meant that scripts and coursework could not be sent to the external for moderation. Compliant externals should also be appointed for additional years after the end of their term of office. Make sure it is clear to externals that assessment guidelines (and anything else they may query) have been imposed by the University central administration and are out of the control of the Department. Regularly change Departmental Exam Officers so that no one individual can acquire enough knowledge to ensure the assessment period is conducted according to the full set of regulations.
13. If an external examiner attempts to question the objectivity and validity of an examination and assessment process, the Registry should reply by stating that there was not a critical mass of external examiners across disciplines raising this particular issue to require a change in University policy. University Registries should ensure that the full range of external examiners' reports are not compiled in any single place where they are freely available for general scrutiny.
14. Finally, make sure that a directive comes down from the University Registry to all examiners to “mark generously and use the full extremes of the marking scales – especially the first class band of marks”. This, of course, is imperative if the institution is to achieve a good grading in forthcoming National Student Surveys!
Please feel free to suggest more practical ideas by which Universities can adjust their assessment and classification processes to generate increasing percentages of first class students. Don't forget, well qualified graduates are our future - we need more of them!




 RSS Feed
RSS Feed